写作技巧2026-03-0416 分钟阅读
2026 AI写小说用哪个模型?Claude 4.6/Gemini 2.5/GPT o3/DeepSeek R1 实测排名
Claude 4.6、Gemini 2.5、GPT o3、DeepSeek R1 等 6 款主流大模型写网文实测排名:按中文文笔、长篇连贯、创意能力、性价比四维打分,附按题材和预算选型的决策树,连大纲、正文、润色各环节混用模型省积分的思路也讲清。2026 年 6 月更新。
马
马良写作团队
马良写作
2026年大模型格局简述
截至2026年初,主流大模型已形成明确梯队:
| 厂商 | 旗舰模型 | 特点 |
|---|---|---|
| Anthropic | Claude Opus 4.6 / Sonnet 4.6 | 长文本、遵循指令、文学创作 |
| Gemini 2.5 Pro / Flash | 多模态、超长上下文、推理 | |
| OpenAI | GPT o3 / o4-mini | 推理能力强、代码、逻辑 |
| DeepSeek | DeepSeek V3 / R1 | 性价比高、中文理解、开源 |
| Meta | Llama 4 Maverick | 开源可本地部署 |
| 通义千问 | Qwen3 | 国内合规、中文特化 |
对于小说创作这个具体场景,各模型表现差异显著。
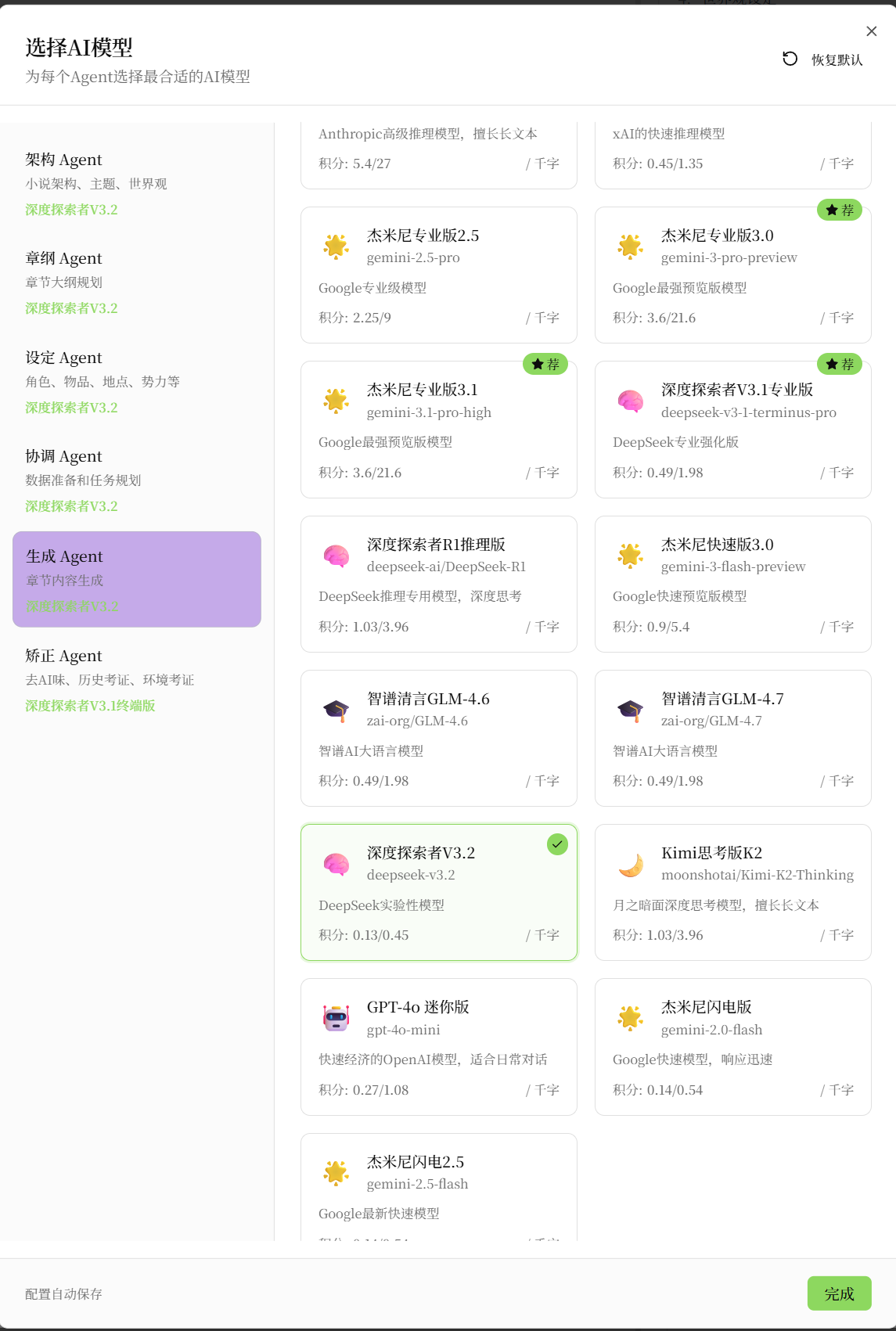
五维评测:写作场景专项
本评测基于相同提示词在各模型上的输出对比,样本为玄幻、都市、科幻三类网文。评分1-10分。
维度1:中文文笔质量
| 模型 | 评分 | 说明 |
|---|---|---|
| Claude Sonnet 4.6 | 9.2 | 句式富于变化,文学性强,最接近"人写"的感觉 |
| Gemini 2.5 Pro | 8.5 | 流畅自然,稍显平稳,爆发力不足 |
| DeepSeek V3 | 8.8 | 中文理解深厚,偶有"教科书感" |
| GPT o3 | 7.5 | 英文训练为主,中文文学性相对弱 |
| Qwen3 | 8.3 | 国内语料丰富,网文风格熟悉 |
写作推荐:Claude Sonnet 4.6
维度2:长篇连贯性(跨章节记忆)
| 模型 | 上下文窗口 | 实际连贯性 |
|---|---|---|
| Gemini 2.5 Pro | 100万token | 极强,可完整记住前100章 |
| Claude Opus 4.6 | 20万token | 强,配合外部记忆效果极佳 |
| DeepSeek V3 | 64K token | 需要配合RAG知识库 |
| GPT o3 | 128K token | 中等 |
注意:在马良写作平台中,所有模型都会结合知识图谱(RAG),弥补上下文窗口的限制。
维度3:指令遵循度
专门测试"按要求写特定风格、字数、情节"的能力。
| 模型 | 评分 | 问题 |
|---|---|---|
| Claude Sonnet 4.6 | 9.5 | 极高,很少偷懒或跑题 |
| GPT o3 | 9.0 | 逻辑严谨,较少出错 |
| Gemini 2.5 Pro | 8.8 | 优秀,偶尔过度发挥 |
| DeepSeek R1 | 8.5 | 推理类指令表现更佳 |
维度4:创意与想象力
| 模型 | 评分 | 说明 |
|---|---|---|
| Claude Opus 4.6 | 9.0 | 情节转折意外性高,不走寻常路 |
| Gemini 2.5 Pro | 8.7 | 多元化输出,思维跳跃 |
| GPT o3 | 8.0 | 偏向逻辑严密,创意发散稍弱 |
| DeepSeek V3 | 8.2 | 基于中文网文语料,套路熟悉 |
维度5:写作性价比
以生成100万字(一部完整长篇)为例估算成本:
| 模型 | 估算花费 | 适用场景 |
|---|---|---|
| DeepSeek V3 | ~¥200-400 | 性价比最高,适合大量章节生产 |
| Gemini 2.5 Flash | ~¥300-600 | 平衡性价比,速度快 |
| Claude Sonnet 4.6 | ~¥800-1500 | 高质量正文,关键章节使用 |
| Claude Opus 4.6 | ~¥3000+ | 旗舰创意,最重要章节使用 |
| GPT o3 | ~¥2000+ | 逻辑复杂场景 |
场景推荐
| 写作场景 | 推荐模型 | 原因 |
|---|---|---|
| 日常正文批量生产 | DeepSeek V3 / Gemini Flash | 性价比高,速度快 |
| 高潮章节精写 | Claude Sonnet 4.6 | 文笔最佳 |
| 世界观设定构建 | Claude Opus 4.6 | 创意思维强 |
| 对话、角色互动 | Claude Sonnet 4.6 | 角色刻画自然 |
| 大纲规划推演 | GPT o3 / DeepSeek R1 | 逻辑推理强 |
| 中文特色场景 | Qwen3 / DeepSeek V3 | 本土化理解深 |
马良写作的多模型策略
专业作者的用法是混合使用:
- 大纲阶段:GPT o3(逻辑推演)
- 设定阶段:Claude Opus 4.6(创意发散)
- 日常章节:DeepSeek V3(性价比)
- 精华章节:Claude Sonnet 4.6(高质量)
马良写作支持为不同Agent指定不同模型,完美支持这种混合策略。
2026年趋势展望
- 模型能力持续趋同:顶级模型之间的差距在缩小,选择越来越取决于价格和特化能力
- 长上下文成标配:百万token上下文窗口将普及,但知识图谱仍是必要补充
- 国产模型崛起:DeepSeek、Qwen系列在中文创作场景已达国际一线水平
#AI大模型对比#Claude vs Gemini#AI写作模型推荐2026#GPT o3写小说#DeepSeek R1创作#大模型选择
RELATED